MTI Journal
MTI Journal.19
Domain Experts x AI to Support
Safe Vessel Operation
– Expert-in-the-Loop –
Hiroki Masaki
Researcher, Maritime and Logistics Technology Group*
*The job title is as of August 23, 2022
I arrived at MTI in October 2019 and am involved in research on systems for detecting abnormalities in ship engines prior to arriving at MTI, I worked at NYK Business Systems, where I was involved in the operation and maintenance of systems such as those for managing the costs required for ship operations at MTI, I work not only with IT technology, but also with the field. MTI hopes to contribute to the safe and efficient operation of NYK’s fleet by absorbing as much domain knowledge and thinking as possible from engineers who know the field as well as IT technology and applying it to daily research and development work.
Utilization of Ship IoT Data on Land
NYK and MTI have built a ship operation monitoring system, LiVE, to visualize SIMS*1 data, analyses the data and issue alerts when anomalies are detected, in order to realize safe ship operations. We are also developing LiVE in such a way that it can be used in conjunction with shipowners and ship management companies for ship maintenance and management. Furthermore, LiVE now incorporates useful tools such as real-time data visualization, online and offline data analysis and anomaly detection functions.
In addition, in line with the digitalization activity at NYK, various initiatives are being implemented to support safe vessel operations, such as crew training and the digitalization of standard operating procedures. In recent years, we have developed an abnormality detection system that monitors the operational status of marine equipment and detects malfunctions at an early stage using IoT data from ships for machine learning, as well as a data quality monitoring system.
Development of Anomaly Detection Systems with Utilizing Machine Learning
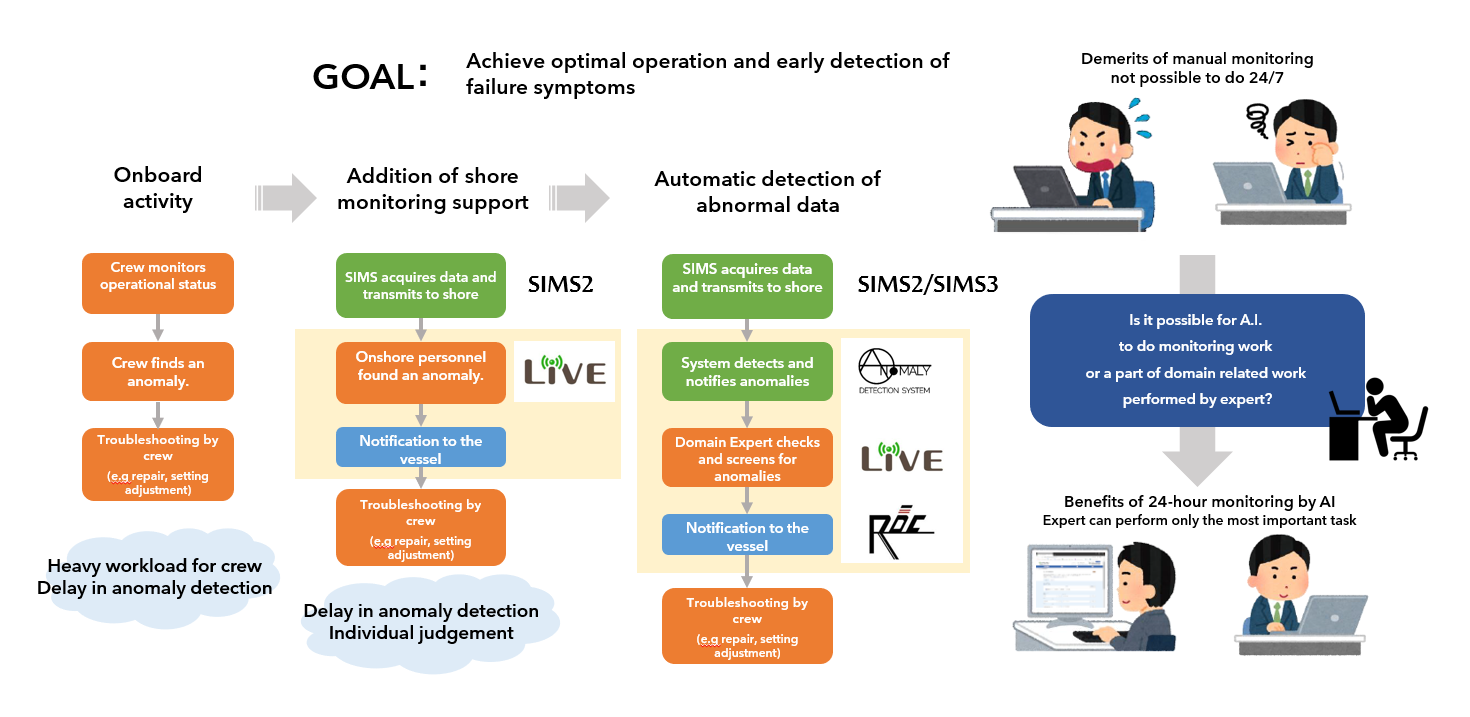
If the vessel’s crew members monitored the data 24/7, it would be possible to detect anomalies before they become major accidents, but to constantly monitor the status of all the engines on an operational vessel to detect these infrequent anomalies, a huge number of human resources would be required. However, the constant monitoring of the condition of all engines on board a vessel to detect these infrequent anomalies would require huge human resources.
Traditionally, engine performance monitoring and maintenance used to be trusted only to the crew, but with the introduction of LiVE, it is now possible to monitor the condition of the engines from shore. This enables sharing of information between ships and land to deal with various situations. In addition, the development of an anomaly detection system has enabled not only early detection of anomalies, but also detailed monitoring of data by the engineer on shore, reducing the number of missed or false alarms. The development of the anomaly detection system is based on the idea that the monitoring work should be left to the system as much as possible, so that the engineer can focus on analyzing the anomaly and considering countermeasures.
Improved Usability and System Production
The anomaly detection system not only detects anomalies in the engine parameter, but also records the results of the domain expert analysis of the detected anomalies (whether they are anomalies that require action or can be regarded as normal). This process of tagging data as ‘abnormal’ or ‘normal’ is known as data annotation, which generally requires a separate person and tool.
In order to make annotation easy and natural for the domain experts when analyzing the results of abnormality detection, this system has a highly usable screen with a slider that can be operated sensitively with the mouse, and a graph of abnormality detection scores and data that can be compared side-by-side. Annotation can now be carried out as part of the analysis workflow without any burden. As securing human resources and time for annotation is often cited as an issue, we consider usability to be very important in a system using machine learning to enable burden-free annotation.
On the other hand, the large number of original functions makes it easy for system inconsistencies to occur as the system specifications and internal logic become more complex. To avoid such risk, we thoroughly tested the operation of the system functions in consideration of the internal logic, the system has been developed to a level of quality that allows it to be operated as a production system.
Nevertheless, through the entire process from the development to the production of this anomaly detection system, we were able to gain knowledge on the usability required for a system using machine learning gain more knowledge of the procedure required to prepare the system into production. I think I can use this knowledge to define requirements for the next new development and to realize more efficient CI/CD (continuous integration/continuous delivery)*2 using the MLOps (machine learning infrastructure)*3 concept.
The Concept of Expert-in-the-Loop
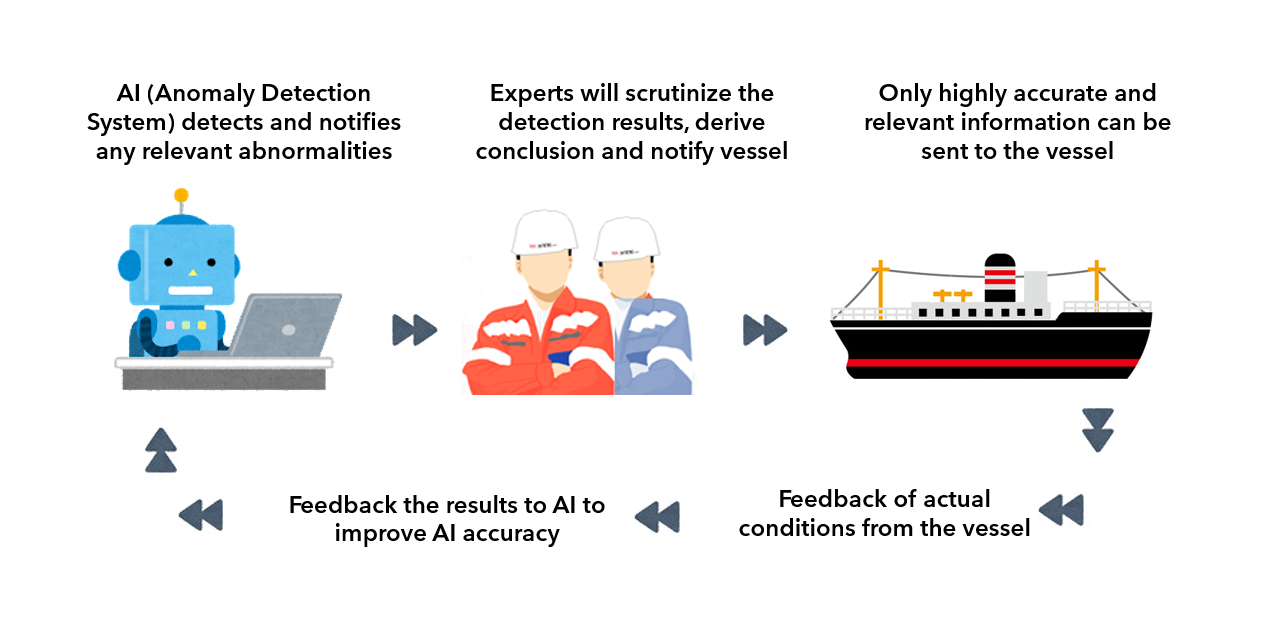
Anomaly detection results obtained from a system using machine learning can be an important indicator in actual anomaly determination, but due to their black-box nature, the system must be controlled, so that false positives do not occur frequently, or detections are not missed. Failure or negligence to tackle this issue is a common phenomenon known as AI blind risk. Currently, AI (anomaly detection systems) monitors the operational status of engine plants 24 hours a day on behalf of domain experts. However, AI anomaly detection results are not perfect, so domain experts play an important role in scrutinizing the anomaly detection results.
This is where the concept of ‘Expert-in-the-loop’ was born. The solution to these problems, in the form of human-in-the-loop, is to have a domain expert stationed, who monitors the data quality and behavior of the system using machine learning as a bridge to communicate the result driven by AI into a comprehensive, and actionable information to the vessel. In summary, the role of domain experts is to rationalize the anomaly detection results output by the system, analyses them thoroughly based on their expertise and report the results to the appropriate parties.
NYK and MTI began developing this concept in 2018 and were able to realize it in August 2020 with the launch*4 of a Remote Diagnostic Centre (RDC) at NYK FIL Maritime E-Training in Manila, Philippines. The aim is not only to utilize the expertise, but also to introduce digitalization initiatives to the young engineers who will support the NYK Group’s safe navigation in the future.

When visiting RDC (third from left: Mr. Masaki)

During the operation at RDC
Realizing Expert-in-the-Loop at RDC
To realize Expert-in-the-loop, RDC uses the two-dimensional System Engineering. The layers in the diagram below represents the indicators for enabling Expert-in-the-loop in RDC and the relationships between the specific systems used.
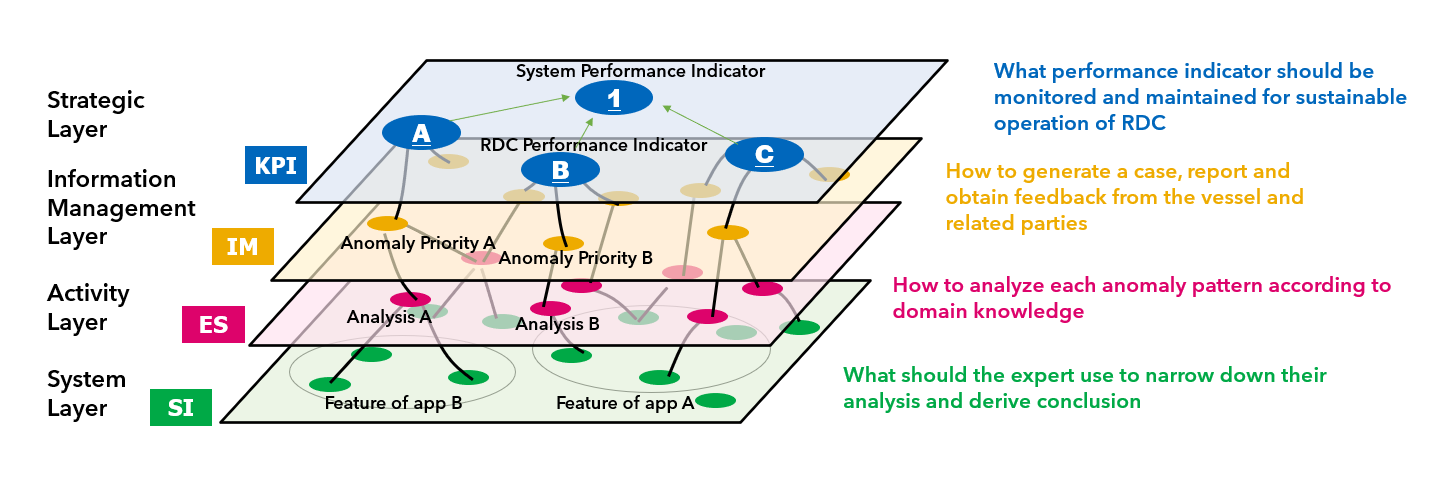
Four layers of the system as a foundation to the RDC operation
The System Layer and Information Management Layer are required to clarify the information needed by domain expert to scrutinize the results of the anomaly detection system and to determine the reporting priorities. This is done by using a variety of applications already developed by MTI and NYK.
The System Layer identifies the systems that are considered useful for the RDC work, organizes the information and functions within those systems that can improve the accuracy of anomaly detection, and compiles this information in the form of a Feature Matrix. As we did not have a complete understanding of all the systems that we considered necessary for anomaly detection analysis, we started the process of creating the Feature Matrix by finding and interviewing people who were familiar with each of the systems. While I realized that I had not studied many of the systems, I was able to learn not only about the functions of the systems, but also about the people involved in the systems and the nature of their work. Furthermore, I was also able to discover issues in system integration studies, such as different data sources even if each system uses similar data items.
In the Information Management Layer, we investigated systems that could be used to properly manage the results of anomaly detection and summarized the necessary functions. As the system would be used in a new organization and for new tasks, we were groping at first, but by conducting trial tests with project members to simulate actual tasks, we were able to smoothly identify the required functions and issues with the various tools.
In the Activity Layer, the thought process in the experts’ abnormality judgement needs to be incorporated into the standard abnormality assessment steps and established as a business process. In the Strategic Layer, in order to maximize the contribution of the RDC, it is necessary to set KPIs for the RDC that are linked to the KPIs of the stakeholders. Therefore, after confirming the Key Goal Indicators (KGI) through interviews with the NYK business units, KPIs were also examined through gap analysis and process confirmation.
In particular, in the Information Management Layer, the results of abnormality detection and feedback from vessels are currently managed manually, but by systemizing the information compiled in this activity and linking it with the abnormality detection system, three benefits can be achieved. The first benefit is the automatic generation of training data for machine learning model. The second is to improve the accuracy of the analysis of the causes of anomalies; if the feedback of the vessel can be visualized and analyzed by BI tools and internal logic, the accuracy of the analysis can be improved. The third is comparison with quantified KPIs. It would be easy to compare the number of detected anomalies that could lead to serious accidents and visualize the contribution of the RDC in real time, which would lead to improvement activities in the organization.
RDC Received the Highest ClassNK “IE Provider Certification” Rating.
Through these initiatives, RDC received the highest rating, Class S, in the Innovation Endorsement (IE) provider certification, which assesses innovative initiatives, from the ClassNK in March 2022*5. After the introduction of this system by ClassNK in 2020, RDC will be the first company or organization to receive the IE provider certification Class S.
When it comes to systems using machine learning, attention tends to focus only on the development of machine learning logic based on high-level expertise. But in reality, it is necessary to optimize the entire system, including the screens and workflow used by the people in charge. By developing an abnormality detection system that considers practical use in this way, we believe we can contribute to the safe and efficient operation of NYK’s vessels.
*1 SIMS (Ship Information Management System): a system developed by the NYK Group for the timely sharing of hourly detailed ship data, such as operational status, fuel consumption and equipment condition, between ships and landings.
*2 CI/CD (Continuous Integration/Continuous Delivery): a method of increasing the frequency of delivering applications to customers by incorporating automation into the application development stages.
*3 MLOps (Machine Learning Infrastructure): an infrastructure and system for managing a series of lifecycles, from model development to operation, through collaboration and cooperation between model development and operation teams.
*4 NYK’s press release on August 21, 2020: https://www.nyk.com/english/news/2020/20200821_01.html
*5 NYK’s press release on March 30, 2022: https://www.nyk.com/english/news/2022/20220330_01.html